Postgres Vs MySQL - My experience on query optimization working on both
October 11, 2018Recently, I had a peculiar incident while tuning a slow running SQL query which was logically doing the same thing but one was in Postgres (v11) and other in MySQL (v5.5). I just wanted to share my findings on how query planning/optimizing works in these 2 RDBMS within the context of my problem. Let me first give you the context of the problem in Postgres database. I was having 2 tables - A Client master table having information about client and a Client emails table having emails belonging to each client - 1 to Many relationship between Client and Email entities.
Below is the client master table schema.
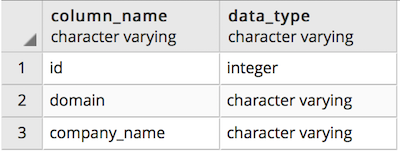
Below is the client emails table schema.
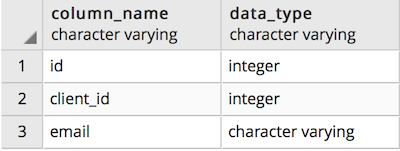
The client_id in the client emails table is a Foreign Key to the id in the client master table.
Now the ask was to generate all client domains who doesn’t have emails in the client emails table. The ask was pretty simple and so I started with this query - was intutive to me.
SELECT * FROM CLIENT_MASTER WHERE ID NOT IN (SELECT DISTINCT CLIENT_ID FROM CLIENT_EMAILS)
Here, I am using a subquery to fetch all the distinct client ids and then filtering out the records in the client master which doesn’t have the client ids. This query was very intuitive for me, so I used this. But it never gave me the result I was looking for and it was just running for an eternity…
I did a check on the record count. The client_master table had 1084701 (~ 1 million) records and 251929 (~ 0.25 million). It was quite huge but not worse to take such a long time to query them.
Now, I did a quick EXPLAIN to see the execution plan of the query. I got the following result.

From the above figure, what I could gather was the subquery would execute first and it will use the index that we have created based on the client_id. After that, the outer or parent query would be executed. This subquery plan looked good to me. But on checking the outer query plan, I found that it was going to do a sequential scan (going to check each and every row from the 1 million set) and apply the NOT in filter.

I was quickly able to tweak this query by converting the NOT IN with a NOT EXISTS. The new query was like this.
SELECT * FROM CLIENT_MASTER CM WHERE NOT EXISTS (SELECT * FROM CLIENT_EMAILS CE WHERE CE.client_id = cm.id)
On doing an explain on this, I got the following output.
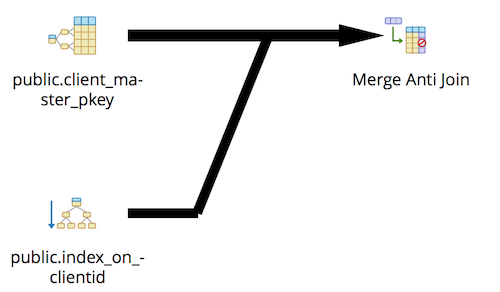
Now, we could see that the result sets are fetched separately from the tables using the indices and the output are merged (Anti join as it was a NOT EXISTS). After running the query, I was able to get the results less than 3 seconds which was acceptable for the business use case.
The take away from this lesson was when using IN operator, the query planner was effectively getting converted into a WHERE CLAUSE with a OR condition for each of the 1 million record in the client_master table thus resulting in sequential scan. When we switches to EXIST operator, the query planner did a fetch from both tables using the indices and then did a merge to filter out the records.
Now, lets get into the context of the problem that I faced in MySQLDB. I was having 2 tables here - A Campaigns table which has all details about campaigns sent to prospective clients and subscribers/client table having list of email. Again 1 to many relationship between campaign and subscribers.
The ask was to fetch all subscribers emails for a set of campaigns. So I used a subquery to first fetch the campaigns and then the subscriber details for this campaign. The query for this was -
SELECT * from subscribers s where s.last_campaign in (SELECT id FROM `campaigns` c WHERE from_unixtime(c.sent) >=( CURDATE() - INTERVAL 10 DAY ))
Again this query was taking an eternity. The record cound in the campaigns was only 280 but the count of total subscribers was ~ 1 million. There was also an index on last_campaign column,
If you look at the query above, it is similar to the one we had seen earlier in PG. On doing an explain on this, it showed that it was doing a sequential scan of 1 million records similar to doing a where with a OR condition for the 1 million records.
As I had seen the issue in this type of query in PG, I didn’t take much of time to rewrite this query using EXISTS. The modified query looked like this.
SELECT * from
subscribers as b where exists (select * from campaigns c
where b.last_campaign = c.id and
from_unixtime(c.sent) >=( CURDATE() - INTERVAL 10 DAY ))
I was confident that this would work like a charm but to my dismay it didn’t. It kept running and running.. :( On doing an EXPLAIN, I found that the outer(parent) query was still doing a sequential scan and going through all the records in the table.

I didn’t understand why was this happening till I stumbled upon this article and this. What I found was mysql does something called “outside to inside” when it comes to executing queries. It would first try to execute/evaluate the parent or the outer query and then use the evaluated value in the sub or inner query. So the final query looked like this.
SELECT b.email, b.id, b.bounced, b.unsubscribed, b.bounce_soft, b.last_campaign from
subscribers as b where b.last_campaign in (select id from (select id from campaigns c
where from_unixtime(c.sent) >=( CURDATE() - INTERVAL 10 DAY )) as x)
To make mySQL execute the inner or sub query first, the above query uses temporary or materialized views which would make the query planner to execute the inner query first and then use the results as a filter in the outer query.
This was one of my firsts in query optimization and it was fun learning and understanding how query planning and optimization works. This my no means a post explaining how query planning and optimization works, but shows how different RDBMS employ query planning and optimization techniques while executing a query. You could read this and this for more in-depth explanation from the official docs.